総合データ分析が明らかにした 従業員の退職と、上司の能力の関係
世間でも注目を集める「データアナリティクス」や「ビッグデータ」という概念が、人事の仕事のあり方を変えつつある。――多くの企業が、顧客の志向性分析や、営業マンの行動分析、マーケティングの費用対効果分析、さらには不正防止予測など、営業・マーケティング・リスクマネジメントなど、事業を取り巻くさまざまな領域でのビッグデータの活用を進めているが、こうした動きは人事の領域においても例外ではない。
先進的な企業では、ハイパフォーマーの特徴を調べるに当たり、通常の人事情報のみならず、社内のメールデータや、フェイスブックやリンクトインなどソーシャルメディアのデータまでを分析の対象として、採用時の候補者の選考基準や、配置計画の判断基準に組み入れるなど、人材マネジメント上のさまざまな場面で活用を進めている。
これまで意思決定の際に「カンや経験」に頼りがちであった、「ヒト」という定性的な領域に、データを活用した定量的な判断基準や予測モデルを組み入れる動きが広がり始めていることは、人事部門にとって1つの大きな変化であると言える。
こうした動きは先進的な外資系のIT企業などで特に顕著であり、その最たる例として挙げられるのが、インターネットサービスにおいて世界的なブランドとなっているグーグルであろう。
グーグルでは、評価や採用などに関するさまざまな人事オペレーションに統計的な解析手法を持ち込むべく、人事部門の約3分の1に数学者もしくは統計学を専門とするスペシャリストを配置するなど、人事のデータ活用に対する動きは他社と一線を画すものがある。
では、振り返ってみて日系企業の現状はどうであろうか。
日系企業の人材データ活用は
世界的に見ても後れを取っている
PwCが2012年に実施した「世界CEO意識調査(全世界のCEO約1300名を対象に行った調査)」によれば、「経営判断における人材データ活用の重要性」について肯定的な回答を示した割合は80%にも及んでおり、人事部門が提示する分析結果に対する経営層からの高い関心が数年前から示されていたことがうかがえる結果となっている。
こうした経営からの期待に対して、人事部門は現状として応えきれているであろうか。その対応状況は国別に見ると大きく異なり、とりわけ日系企業における人事データ活用の遅れが顕著に表れる結果となっている。
人材の多様性と、
人事データの活用度には深い関係がある
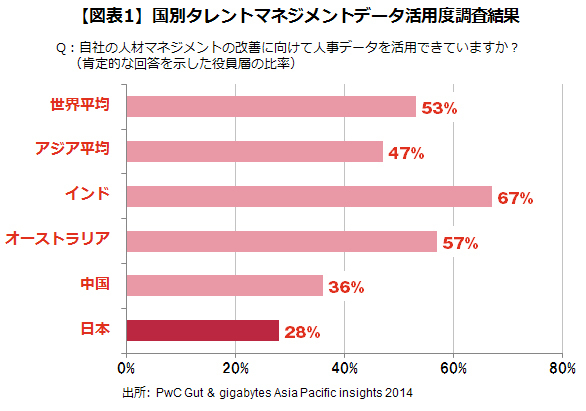
【図表1】に示す調査結果は、前述の調査から2年経った2014年に、全世界の役員層(執行役員を含む)約1130名に対する「人材データの活用度に関する満足度」を国別に示したものであるが、日系企業の調査結果を見てみると、全世界平均の53%の約半分である27%にとどまっている。
またインド、オーストラリア、中国というアジア太平洋地域の先進的な国と比較しても、日本は最下位に位置づけられ、人事のデータ活用の側面においては、先進諸国に大きな後れを取っているのが現状である。
このような差が生まれる要因の1つとしては、社内における多様性(ダイバーシティ)が大きく関係していると考えられている。日系企業では1990年代まで、多くの企業で終身雇用の概念が強く残っており、多くの人たちが大学を卒業して就職し、そのまま同じ会社やグループ会社の中で経験を積んでいくケースがほとんどであった。
結果として「金太郎アメ型社員」というような言葉にも示されるように、同じようなバックグラウンドや考え方を持った社員により形成される同質性の強い組織風土が多く生まれてきた。これは「阿吽(あうん)の呼吸」といった言葉にも代表されるように、コミュニケーションの効率性という面においてはうまく機能してきた側面もある。
一方で、結果として定量的なデータに基づくコミュニケーションよりも定性的なコミュニケーションが好まれる傾向を生み出してきたとも言える。
他方、欧米などの多くの先進グローバル企業などでは、人種、出身国、母国語、経歴などさまざまなバックグラウンドを持った人材が集うことも多いため、阿吽の呼吸のような共通的なバックグラウンドを前提とした会話や意思決定など通じるはずもなく、定量的な数値を使ってコミュニケーションを取らざるを得ない環境であった。
結果として彼らの意思決定の際には、定量的なデータが多く用いられるようになり、グローバル化が進む近年、その傾向はさらに強まってきている。
人材のデータ活用には
5段階の成熟度がある
データ活用における課題や現状を把握するためにも、まず人材のデータの活用度には、いくつかの段階があることを先に述べておきたい。【図表2】に示すチャートは、当社が提唱している「人材データ活用成熟度モデル(HCA Maturity Model)」であるが、この中では人材データの活用には5つの段階があることを示している。

まずレベル1~2の「単年集計」「経年比較」であるが、これは退職率や採用人数推移などのように、従業員一人ひとりの属性データを単純に集計し、単年度の状況や経年での変化などを分析するものである。1990年代後半から注目を集めたERPシステムの導入などにより、現在ではほとんどの企業で、問題なく実現できている領域であろう。
次に、レベル3の「競争力比較分析(ベンチマーク比較)」であるが、これは報酬水準や離職率、教育投資など人材マネジメント上のデータを他社とベンチマーク比較し、自社の競争優位性を確保する上での判断基準を持つための分析を行うことを示している。
イメージが湧きやすいように、外資系製造業A社での人事におけるベンチマーク比較の例を取り上げてみたい。
A社では人事に関するさまざまな課題を洗い出すために、人事部門の機能別人員数、例えば採用や育成、人事情報システムなどに従事している人員数の過不足や、採用コスト、育成コスト、社員1人当たりの育成時間、さらには人事サービスに対する従業員や役員の満足度など約30項目にわたるKPIについて、数年おきに競合企業との比較を実施している。
A社ではこうした取り組みにより、退職率や従業員満足度のような、さまざまな人事施策やオペレーションの結果として生まれるデータだけなく、その要因となっている人事プロセスや、人事組織の構造や要員構成、人事のスキルに至るまでを分析して、より明確に人材マネジメント上の課題を浮き彫りにすることを可能としているのである。
そして問題となるのが、【図表2】に示したレベル4の「要因分析」、レベル5の「予測分析」であるが、分かりやすいように退職率に関する分析を1つの例として取り上げて解説を進めたい。
まず「要因分析」であるが、これは退職率の悪化などのある特定の課題に対して、その要因となる要素を定量的に分析し特定するものであり、「退職率は○○%であるが、最も影響を与えている要因は何で、どの程度なのか?」という問いに答えるものである。また「予測分析」はさらに、「この施策を打てば退職率は○○年までに○○%まで下がる」という形で、施策実施の効果などを定量的に予測することを指している。
過去の退職者の特性をモデル化して
もっとも退職に影響を与えた要因を特定
実際に従業員約4000人のサービス業B社では、ここ2年間でこうした分析を強化してきており、過去の退職者のさまざまな特性をモデル化することにより「従業員の退職に最も影響を与えているのは、上司の能力であり、その割合は約28%である」ということを特定できている。さらには、そうした課題への改善策を講じることにより「2年間で退職率を現状より19%低減できる」という予測値までを打ち出すことを可能としている。
おそらく多くの企業で、退職要因の特定という面では、問題なく課題を把握できているであろう。現場の部長層や、人事担当者に聞けば、迷うことなく「報酬」「職場の雰囲気」「リーダーシップ」などさまざまな答えが即座に返ってくる。しかしそうした中で「優先度をつけると」という質問になると、「いろいろな要因が複雑に絡み合っているから」という曖昧な答えに変わってしまう。
もし時間にも予算にもゆとりがあるのであれば、想定できる課題に対して、さまざまな施策を試していくことができるであろう。しかし、現状の多くの企業が直面しているグローバル競争下においては、国内のみならず海外各国で起こる事業環境や労働環境の変化に対して、限られた予算の中で迅速に対応する意思決定が求められてくる。そうした中で、人事データ活用におけるレベル4や5の領域は、こうした意思決定モデルを支える重要な差別化要素の1つとなり得るのである。
また、レベル4、5に示すような分析は、退職要因の分析のみならず、人員の需要予測や、採用時の候補者の選考基準、トータルリワードの設計に至るまで多岐にわたる。
こうした分析手法の内容については第2回以降の連載の中で触れていきたいと思うが、冒頭にも述べたように人事データの活用は、人材マネジメント上のさまざまな領域で、その在り方を変えつつあるのである。